

Building an Anthropic-style coding harness - and what it means for a future autonomous product discovery agent
Walkthrough of my multi-agent harness, and a concrete blueprint for more independent AI product discovery

When I started vibe coding small apps I spent all my time ping-ponging with the agent (”fix this,” “alignment looks off,” “colour looks weird”). The context switching made my brain feel as overheated as my 8GB MacBook. Every developer I know faces the same problem: the agent is fast, but the human review loop is the constraint.
The question du jour: How do you get an AI agent to produce work you can trust without reviewing every single output?
Anthropic’s answer is a “harness” - a system you build around the agent so its output is more likely to be good. This article inspired me.
Coding agents are built for coding, so this is where best practices evolve first.
But I use AI agents for PM work too - synthesizing interview transcripts, identifying customer opportunities, generating test strategies. I’m the bottleneck in that workflow the same way developers are in code review.
The harness is how I think we solve that. I’ll walk through the coding harness I built first, then show what this could look like for an autonomous product discovery agent.
Contents
- What my coding harness looks like
- What a PM discovery harness might look like
- The hard part: codifying “good” when there’s no linter
- Where I am with this
What my coding harness looks like
I built one for my buddy Claude Code for my vibe-coding projects. Here are the key components.I think every one of them transfers to non-coding agent work.
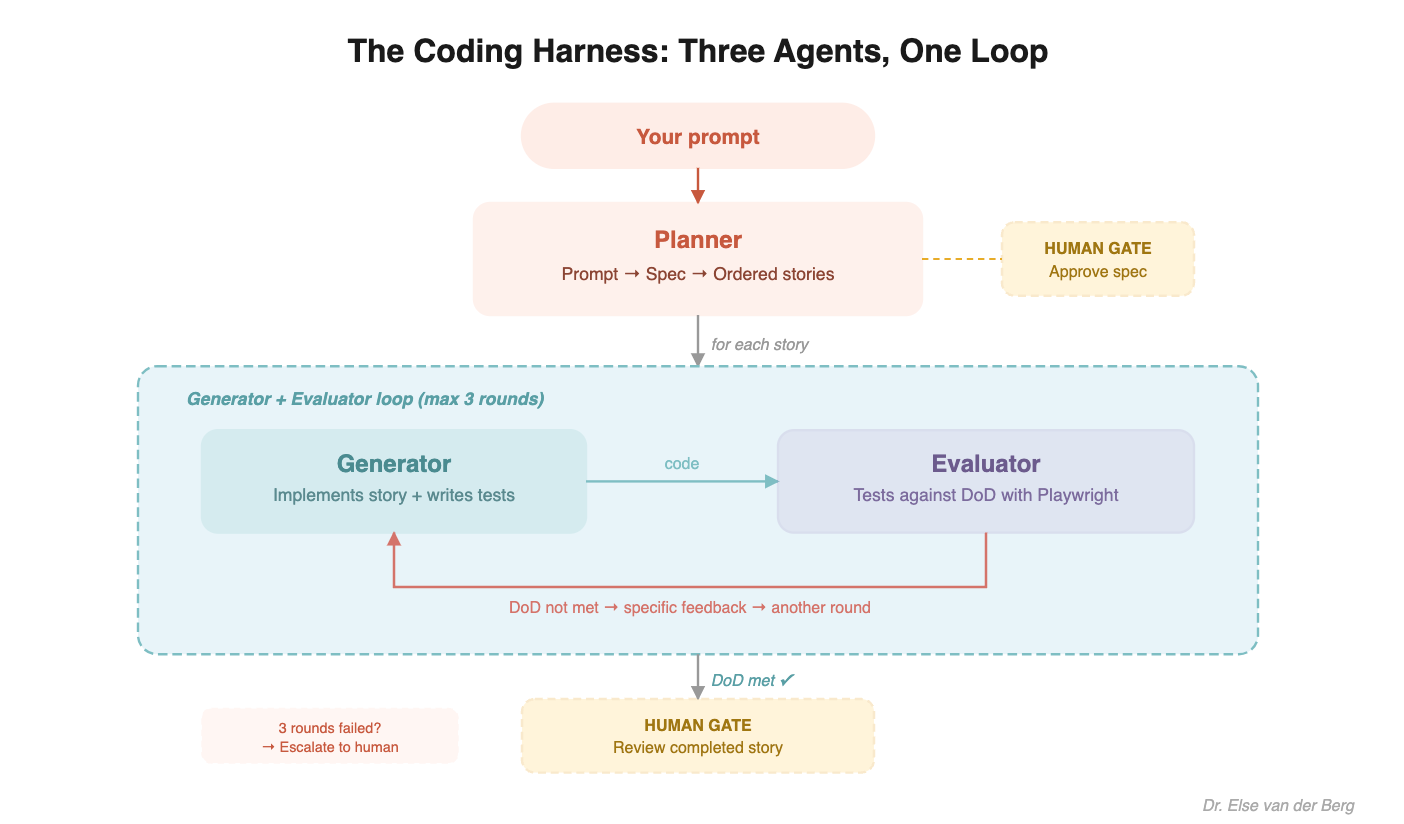
Three agents, not one
Instead of one agent doing everything, I split the work:
Planner - takes a brief prompt, expands it into a full product spec, then breaks it into ordered stories (like a PM would: feature -> epics -> stories)
Generator - implements one story at a time, writes tests alongside code
Evaluator - a skeptical QA agent that tests the generator’s work against a pre-agreed Definition of Done, using Playwright to actually interact with the running app
Each agent has a focused role and clear boundaries. The planner doesn’t write code. The generator doesn’t evaluate. And the evaluator doesn’t rationalize - which took deliberate effort. Out of the box, Claude is a terrible QA agent. It identifies legitimate problems, then talks itself into approving anyway (”it’s pretty good for a first pass”). I had to explicitly tune the evaluator to fight this: “If something fails, it fails. Do not rationalize, minimize, or excuse.” Without that tuning, the self-checking loop is theater.
File-based communication
I borrowed this bit from OthmanAdi’s “planning with files”.
The agents communicate through files in a shared workspace, not direct conversation:
```
project/
.harness/
spec.md # The approved spec (source of truth)
findings.md # Planner’s research log (why it chose React over Svelte, etc.)
stories/
01-user-login.md # Story definition
01-user-login-dod.md # Definition of Done (negotiated between generator + evaluator)
01-feedback-r1.md # Evaluator’s test results, round 1
```
When I review, I read the files. The thinking is externalized - I don’t have to reconstruct, or keep staring at the agent’s “thinking process” to find out what happened or why.
Specification upfront, not iteration after
The planner creates a detailed spec first. The human approves it. Only then does the generator start coding. An agent building against a spec with clear acceptance criteria produces dramatically better output than one iterating on vague feedback.
Self-checking loops
The generator doesn’t just build and hand off to me. After each story, the evaluator runs automated tests with Playwright - actually navigating the running app, clicking buttons, filling forms, checking edge cases. If the Definition of Done isn’t met, it sends specific feedback back to the generator for another round. Up to three rounds before escalating to a human.
This is the part that reduced my review time the most. By the time work reaches me, it’s already passed automated QA. A lot less ping pong.
What a PM discovery harness might look like
I haven’t built this yet. But after building the coding harness, I can see the shape of it. The same principles apply, I just need to translate them.
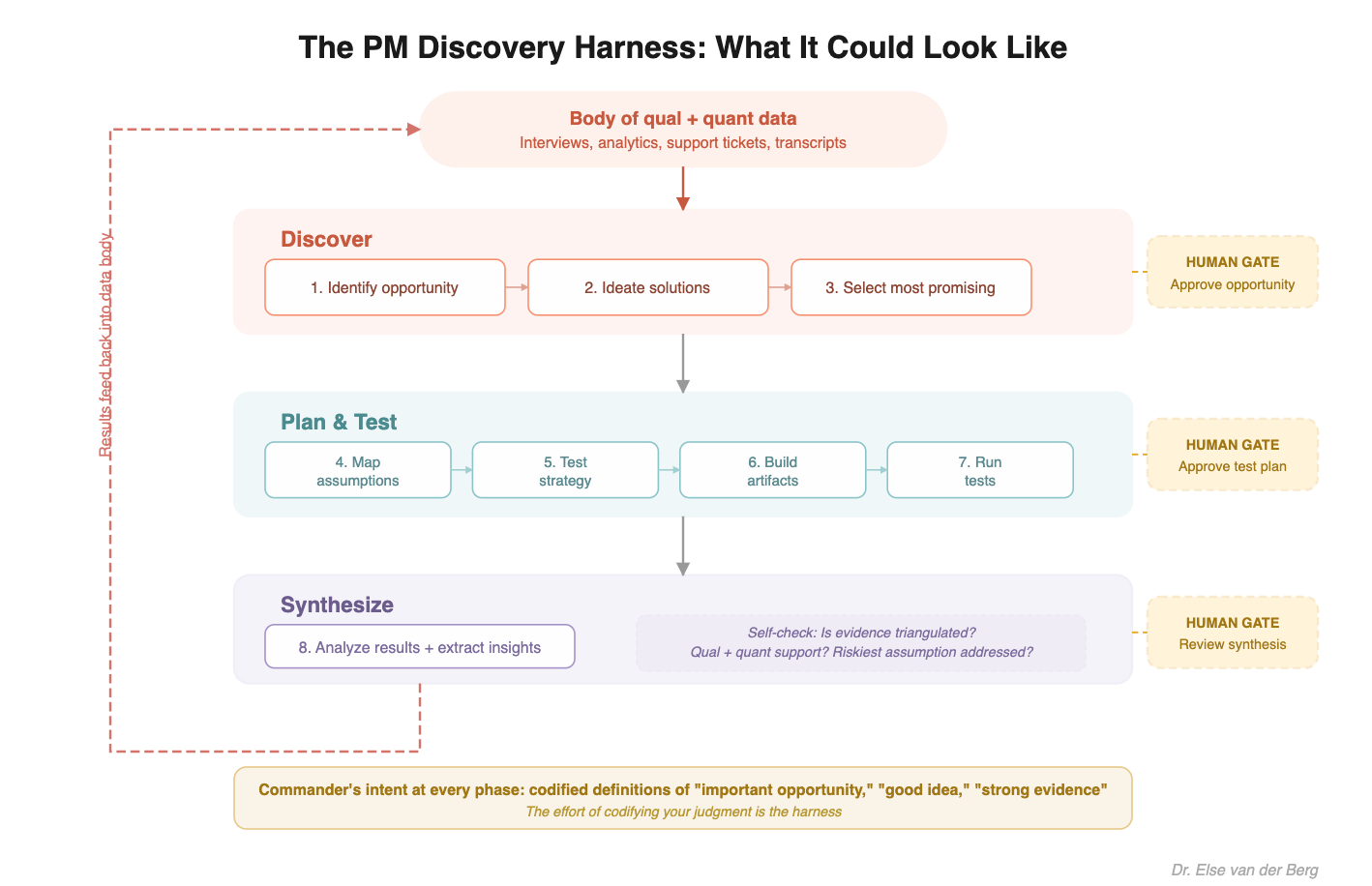
What my product discovery workflow looks like today:
1. Identify customer opportunity (problem, desire, wish) to focus on
2. Ideate many solution ideas
3. Pick the most promising idea(s)
4. Map assumptions underpinning each idea -> identify riskiest assumptions (least evidence + most important)
5. Identify a test strategy for riskiest assumptions (I went deep into this here: https://assumption-tests.com/)
6. Set up the tests (create artefacts if needed, invite participants, create experimentation doc with success metrics, etc. etc)
7. Run tests
8. Analyze results and let those flow back into our body of qual. and quant. data (which is used in 1.)
So far, for each of these steps I’ve used AI as a tool to support me (I’m in the “glorified autocomplete” phase). I’m the orchestator, I review everything.
I see a future where an AI agent can handle the orchestration between the steps, and review itself within each step to make sure that the thing it asks me to review is *very good*.
To get there, the “harness” idea transfers really well.

Split the work. In code: Planner, Generator, Evaluator. In discovery: Opportunity analyst, Solution ideator, Test strategist - each with clear boundaries.
Specification upfront. In code: an approved product spec before any code is written. In discovery: an opportunity brief with evidence before solutions are ideated. Success criteria before any test is run.
What good looks like. In code: conventions, design criteria, linting rules. In discovery: ICP definition, evidence quality standards (what counts as “soft” vs “hard” evidence), triangulation requirements.
Self-checking. In code: the evaluator tests against the Definition of Done with Playwright. In discovery: does the insight have both qualitative and quantitative support? Does the test strategy address the riskiest assumption first?
File-based communication. In code: spec.md, findings.md, stories, feedback files. In discovery: opportunity-brief.md, evidence-map.md, test-results/, synthesis files.
Human gates at strategic points. In code: after spec approval, after each story. In discovery: after opportunity selection, after test strategy, after synthesis.
The hard part: codifying “good” when there’s no linter
The table above makes it look simple. But there’s an obvious problem: in coding, “good” is partly objective. Tests pass or fail. The linter catches violations. Playwright can see if a button works.
In PM work, “good” is much more subjective. What makes an opportunity “important”? What makes an idea “good”? What makes something an “insight”?
This is the same challenge I faced when setting up a coding agent for more independent design work. Code quality has a linter; visual design doesn’t. So I had to translate my subjective taste into concrete rules the agent could follow.
Shane Parrish explains the idea of “commander’s intent” in his book “Clear Thinking”:
“When the entire team understands clearly the markers of success and failure, they are empowered to act the minute things veer off course.”
For my coding harness, that meant things like: Copy should prioritize clarity with no unnecessary words. A kill list of forbidden corporate words. Before/after pairs showing what I wanted. Concrete enough that the agent could self-check without asking me.
The same approach applies to PM discovery work, you just have to do the hard thinking upfront:
“Important opportunity” = Relates to our ICP, affects min. 30% of ICP, mentioned in both qualitative interviews as a strong pain/wish/desire OR visible in quantitative data
“Good idea” = directly addresses the root cause (not a symptom), feasible within current technical constraints, small unit of value testable within 1 month
“Strong evidence” = triangulated across at least 2 data sources/test methods, real-world signal (vs. what users say they want)
None of this is easy. But that’s exactly the point - the effort of codifying your judgment is the harness. And once it’s written down, the agent can apply it consistently across hundreds of data points in a way you never could manually.
Here’s what it could look like:
Where I am with this
The coding harness is working. I’m using it at SwitchUp to build internal tooling and the switchup.tech website. I can now hand it a list of changes, work closely with my planner to create a solid file based plan, and then come back when the work is *done*.
The PM discovery harness is still in my head. I use Claude Code for non-coding PM work already - synthesizing interview transcripts, connecting qualitative and quantitative data, generating test strategies. But it’s still me orchestrating every step. The harness thinking is how I’ll eventually step back from that.
I’m early with the transfer. If you’re further along - building something like this for research, discovery, or any non-coding agent workflow - I’d love to hear from you.
Cheers to the dream:

Work with me? I’m hiring AI-forward full-stack and staff engineers to come join me at SwitchUp (switchup.tech). Connect with me on LinkedIn if you’d like to chat.