

Vibe Coding an AI-Native RAG Product as a Non-Technical PM
How I Built an MVP That Isn’t Total "AI Slop" Without Knowing How to Code

First things first: I still believe that if you can’t judge whether code is good (I certainly can’t), you shouldn’t “alpha launch” your product. I’m tired of non-technical people releasing buggy, insecure products en masse. It’s destroying early-adopter appetite and ruining the game for people who build things worth touching.
But.
I also believe you can “vibe code” a functional MVP to collect early feedback, as long as you are transparent that it’s a beta. And thanks to AI coding agents, the unit economics of “throwing some spaghetti at the wall” have fundamentally changed.
This was my exact problem.
Why I Vibe-Coded my MVP Vera TechAssist
I’m building a bootstrapped B2B SaaS, and my biggest hurdle is getting my ICP (managers at solar companies) to talk to me. I’ve been facing terrible cold outreach -> call conversion rates. Personalization feels superlame (“Hi xxx, I imagine that as a (insert role name) you must be facing (problem x)”, personal video-notes didn’t cut it.
Why would a busy manager say ‘yes’ to a call with me when there was nothing in it for them?
I decided to build an MVP, not to sell, but to give away. A “value-first” offering to start a conversation and, just as importantly, to see if anyone cared about the idea at all.
Pre-AI, this would have been way too expensive for an idea I was still unsure about. But now, with my dear friend Replit by my side, I was comfortable with the risk of building an MVP to throw proverbial spaghetti against the wall.
This led to my central research question: How can I, as a non-technical PM, use an AI agent to build a functional RAG product that isn’t complete “AI slop”?
The Case Study: Vera TechAssist
The “spaghetti” I built is Vera TechAssist, a free (beta!) tool to help solar technicians get instant, cited answers from trusted technical manuals.
Goal: A value-first giveaway to my ICP. Test whether there is any appetite for the idea at all, book discovery interviews.
Time: 1.5 months, at about 10 hours/week.
Tool: Replit (Agent 3.0 <3)
Cost: $486.05 (mostly Replit)
How Vera TechAssist Works
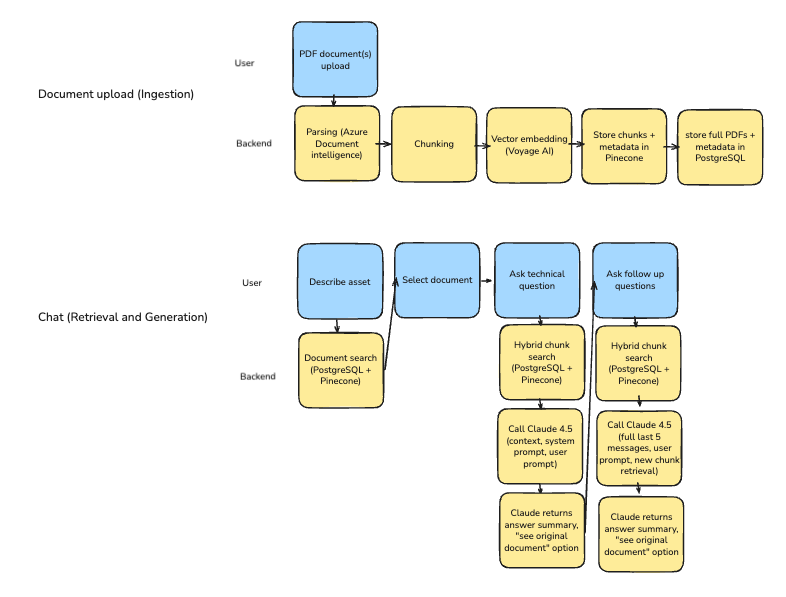
Vera is a Retrieval-Augmented Generation (RAG) pipeline.
Ingestion: Back-office staff upload technical PDFs. I use Azure Document Intelligence to parse them, as it’s great with complex tables and stylized text. An LLM pulls metadata (like model numbers), and the content is broken into chunks.
Storage: The chunks are stored in two places: as vector embeddings (using Voyage AI) in Pinecone for semantic search, and in a PostgreSQL database for keyword search, full PDF storage, and metadata.
Retrieval & Generation: When a user asks a question, the system does a “hybrid search” against both Pinecone and Postgres to find the most relevant document chunks. Those chunks, plus the user’s question, are fed to Claude 4.5.
Citation: I instructed Claude to only use the provided context and to cite its sources. Users get a summarized answer with a “see original text” button, which opens the PDF to the exact page and section, letting them verify the answer and see any graphs or tables.
(See mermaid diagram, just for kicks)
Reducing The Risk of Generating AI-Slop
I couldn’t write the code, but I could be an extremely demanding manager who is “deep in the detail”, a systems thinker, and critical tester/evaluator.
My entire approach to reducing “slop” rested on a framework of active, critical oversight.
Pillar 1: I Am the Architect (Making Critical Decisions)
An AI agent will pick weird-ass paths. It simply doesn’t know about the latest libraries or third party tools, and it will select the wrong one out of the things it does know about. My first job was to override this and make the big architectural decisions.
I used Replit’s Plan mode heavily and asked Claude to weigh in on most decisions. This also helped me escape painful debugging loops.
I made some “expensive” mistakes though.
Wrong database: Sure enough, Replit’s first database choice was SQLite. This is fine for a toy, but it means all user data gets deleted on every redeploy. I had to research and explicitly instruct the agent to migrate to a production-grade PostgreSQL database.” Even then, it tried to use one shared database for Dev & Prod. I had to catch that and manually instruct it to separate them. You have to watch the agent like a hawk.
Choosing the Wrong Services: This was my biggest mistake. I started with Llamaparse for document parsing. It was easy, but it choked on the stylized tables in my manuals. I had to halt development, research alternatives, and order a significant migration to Microsoft Azure Document Intelligence.
Let’s chalk it all up to “learning”.
Pillar 2: I Enforce Engineering Discipline (Managing the Agent)
Keep reading with a 7-day free trial
Subscribe to Else’s Productpourri to keep reading this post and get 7 days of free access to the full post archives.